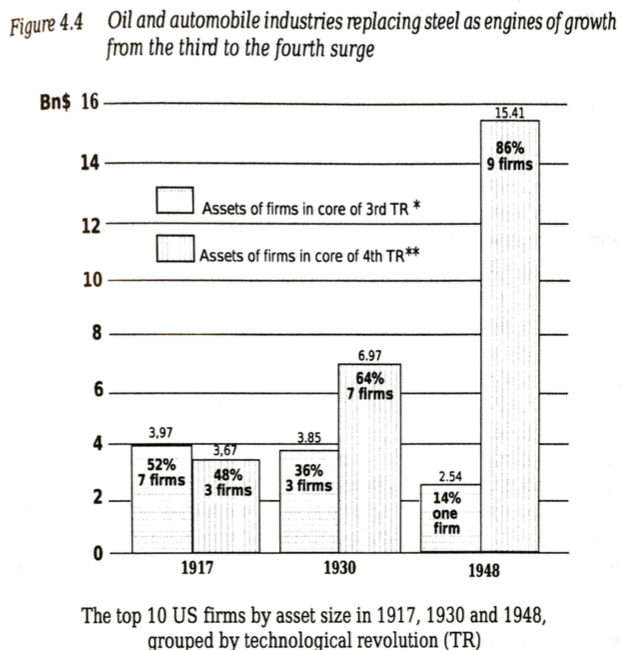
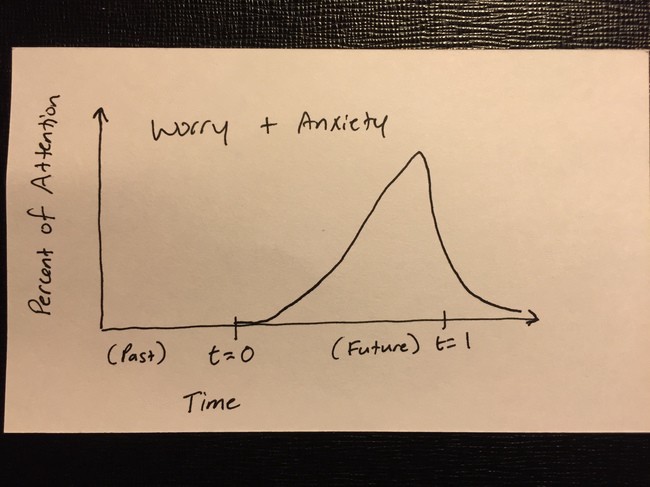
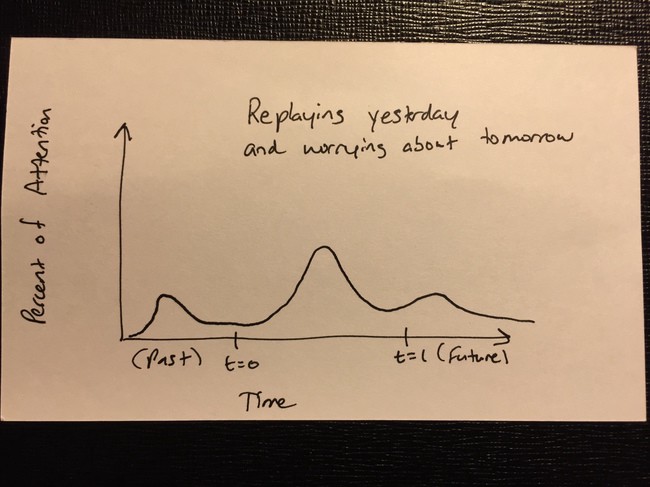
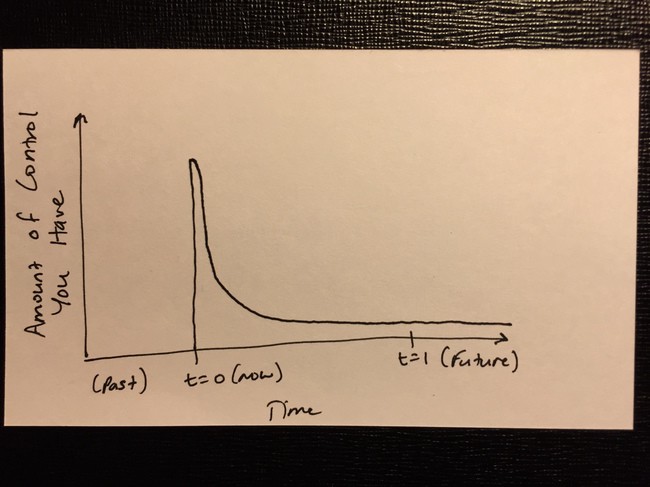
Any time I take a long train ride it feels just a little bit like being in a time machine. Compared with the indignities of commercial air travel, the train seems to belong in a different era. Like it wouldn’t seem at all surprising if someone boarded the train who was actually a time traveler from 100 years ago.
Now, they might be a little confused that everyone was quietly staring at — or loudly talking at — a small glass box. But certainly they would recognize they were on a train, with seats for passengers, a dining car, and a conductor coming through to collect tickets.
And yet it would take little convincing to persuade our fictional time traveler that he was indeed visiting the future.
(As a sidenote, it is ironic that wifi is so terrible on trains. For a time, trains were the fastest and most reliable means of communication available. That’s because when trains first began connecting — and in many cases reshaping — the country in the 19th century, the word “communication” was inextricably linked with “transportation”. If you wanted to send information from one place to another, you literally needed to send the message. It wasn’t until the telegraph that information and transportation were finally separated.)
From our modern perspective it’s difficult to appreciate just how profound the separation of communication from physical transportation really was, but in “Technology and Ideology: The Case of the Telegraph”, Media Scholar James Carey offers a helpful anecdote:
It was of particular use on the long stretches of single-track railroad in the American West, where accidents were a serious problem. Before the use of the telegraph to control switching, the Boston and Worcester Railroad, for one example, kept horses every five miles along the line, and they raced up and down the track so that their riders could warn engineers of impending collisions. [Emphasis added]
But perhaps what’s most interesting to me about a conversation with our time-traveling friend isn’t the idea of explaining what’s new, but the realization that so much would be quite familiar. For example, it wouldn’t be hard at all for him to understand that one of my monthly bills is a payment to the American Telephone and Telegraph company — more commonly known as just AT&T these days — for the privilege of sending short text-based messages to family and business associates. Or even that those messages often include opaque abbreviations, though in today’s case that’s to save time, rather than money.
So what does that have to do with the publishing industry?
Well, as another sidenote, Carey mentions that Ernest Hemingway once worked as a telegraph operator, an experience that gave him a lot of practice paring down his prose, honing his signature writing style.
But that’s not why I bring it up.
This post began its life many months ago as an unfinished draft of an email reply to a thread on a publishing industry email list. I can’t recall the exact message, but the subject was something along the lines of “Digital is ‘Done’”.
And that’s a sentiment I’ve heard several times from many in publishing. That sure, ebooks and Kindle are here to stay, but print is unquestionably still the main event. And that for all the hype that surrounded “digital disruption” over the past decade or so, it’s time now to more or less return to normalcy.
There’s less talk these days about “chief digital officers”, and in fact at some firms that role has now disappeared, with the explanation that “everyone is digital” now.
Certainly much has changed over the past 10 years. When I was at O’Reilly Media and working to help plan the very first Tools of Change conference almost 10 years ago, there was no Kindle, no iPhone. Borders was still alive and kicking. Twitter was in its infancy and Facebook had just opened up registration to non-college students. There was no Instagram, no Snapchat, no Uber.
But it’s also worth noting how much looks the same. Back then there were 6 major trade publishers atop the industry. Today there are … the same major trade publishers atop the industry, though two of them merged.
For all that has changed — no publisher would fail to include social media outreach or SEO in their marketing plans — it’s striking just how much would be entirely recognizable as “publishing” to a time traveler from, say, 20 years ago.
How is it that whether it’s publishing or trains or telegrams, so much can empirically be different, while yet more still remains decidedly unchanged? And more importantly, why?
It’s worth some time thinking about a handful of the other large industries that have nominally been under threat of “disruption” over the past 10–20 years.
Thinking more broadly than trains, let’s look for a moment at travel. Sure the world today looks very different if you’re a travel agent, but again I think a time traveler from 20 or even 50 years ago would recognize most of it, with some minor differences.
It would seem unusual that most of us book our own tickets and hotels, or that we take our shoes off at the airport to be looked at naked by bureaucrats, but we fly American or United or Delta Airlines, we show up at the airport and kill time at a bookstore — or a bar — and we claim our baggage using little paper tags at the other end of our flight.
Or let’s look for a moment at real estate. There’s no question that technology has changed real estate, and significantly altered many parts of the buying and selling process. But in most parts of the country, people still buy and sell houses largely the way they always have, including using agents, borrowing money with a mortgage from a lender, and signing a giant pile of paperwork at a lawyers office. And then having their deed recorded by a county official.
Or look at another industry that was very much intertwined with real estate during the housing bubble, and that’s the financial industry. An industry under such intense strain and scrutiny would seem especially susceptible to disruption and displacement from new entrants. And yet in nearly every case, the most common outcome for a successful “fin tech” startup is … to be bought by a bank or existing financial services firm.
How is it that we see so many industries both irretrievably altered and yet entirely recognizable to someone visiting from before the change?
Homeostasis and The Lens of Systems Thinking
One of my very favorite books is “Thinking in Systems” by Donella Meadows, published in 2008 by Chelsea Green. In it Meadows defines a system as follows:
A system is a set of things — people, cells, molecules, or whatever — interconnected in such a way that they produce their own pattern of behavior over time. The system may be buffeted, constricted, triggered, or driven by outside forces. But the system’s response to these forces is characteristic of itself, and that response is seldom simple in the real world.
As Meadows notes, the real-world responses of systems are rarely simple, yet we tend to actively seek simplicity when explaining events around us:
- Book sales are down because people don’t read!
- Book sales are up because of adult comic books!
- Book sales are down because of piracy!
- Book sales are up because of Facebook!
- Ebooks will save publishing!
- Ebooks are killing independent bookstores!
(I offer these examples with humility, and will readily admit being guilty of offering such simplistic explanations on occasion.)
Yet it shouldn’t be surprising that we find linear narratives based on cause-and-effect so appealing. It’s a fundamental part of our nature.
This comes from a 2010 study conducted at Yale:
In one experiment babies between six and ten months old were repeatedly shown a puppet show featuring wooden shapes with eyes. A red ball attempts to climb a hill and is aided at times by a yellow triangle that helps it up the hill by getting behind it and pushing. At other times the red ball is forced back down the hill by a blue square. After watching the puppet show at least six times the babies were asked to choose a character. An overwhelming majority (over 80%) chose the helpful figure. Professor Paul Bloom said it was not a subtle statistical trend as “just about all the babies reached for the good guy.” [Emphasis added]
That kind of response is called “non-linear”, and it’s so deeply ingrained into the world around us that it’s nearly invisible, at least compared with linear behavior, which is much better suited to the logical, rational part of our brain.
Your car seems to respond in a linear way: if you drive twice as fast, you’ll arrive in half the time. But the traffic all around you is a system that responds in a non-liner way. As you add cars, the flow slows gently, until at some critical point — typically just after you’ve turned onto the highway — it suddenly collapses into gridlock.
As you add fertilizer to your tomato garden, more fertilizer means more tomatoes — up to a point. More fertilizer means more tomatoes until it means no tomatoes at all.
Again, this kind of behavior is all around us — water gets slowly colder until it suddenly freezes. Or slowly warms until suddenly it boils. But time and again, our explanations tend toward very linear cause and effect.
- If the stock market tumbles, it’s because of that day’s big news story.
- If sales are up, it’s because of effective marketing.
- If a project is running late with a team of 2 people, we add 2 more — and the project becomes even later.
That last phenomenon was described in a classic 1975 technology book by Fred Brooks published by Addison-Wesley called “The Mythical Man Month”, which illustrated that you cannot speed up a software project by adding more people, and in fact you will inevitably slow it down.
Any group of people after all is a collection of living organisms, so there’s good reason to think that the same rules that apply to other complex natural systems like ecologies or weather also apply to people.
Dana Meadows defines three fundamental characteristics of any system.
First, it must have elements, components that comprise the system. These may be physical, tangible things like people or computers. Or they may be intangible things like temperature or mood.
Second, it must have interconnections. Ways for information and action to be transmitted among the various elements. For a company, that could be a hallway conversation, a financial report, or perhaps the tone and posture of a meeting participant.
Third, it has a purpose. A goal. In the case of a company or a group of people, this may or may not resemble what anyone at the company — especially the CEO — might say or think the purpose is, and is usually closely tied to what behaviors are actually rewarded. For example, I went to the Wells Fargo website and took a look at their 21-page “Vision and Values” document, which reads in part:
The reason we wake up in the morning is to help our customers succeed financially and to satisfy their financial needs, and the result is that we make money. It’s never the other way around.
Uh-huh.
We’ll look a bit deeper at each of the three parts of a system, but keep in mind that our inclination at the first sign of trouble in a system is typically to start swapping out the elements, as if they were faulty parts of an engine (Wells Fargo is quick to point out just how many people they’ve fired). But the second two — the connections and the meaning — are far more important in determining the health of a system.
One of the most important mechanisms within a system is something called “homeostasis”, which means the state of the system when everything’s — for lack of a better word — normal.
Let’s use a very simple example of a mechanical system with a feedback loop for maintaining homeostasis.
Your home has a thermostat, perhaps even a fancy one that you can adjust from your smartphone. As winter sadly fast approaches, most likely you will soon turn on the heat in your home. You would probbaly define “normal” as having your home at somewhere around 68 degrees, though in practice anything in the range of 67–70 would be fine.
Your home gets cooler by losing heat to the outside. Once the temperature drops below 68, the thermostat tells the furnace to turn on, adding heat back to the system. Once the desired temperature is reached, the thermostat instructs the furnace to turn off.
It’s fairly sophisticated behavior using incredibly simple components. The furnace has just two states: on or off. The thermostat only knows how to track a set point: if the temperature drops below the set point, the switch turns on; if it’s above the set point, the switch turns off. As “smart” as your thermostat may be, that basic operation is unchanged. Yet your house will now adjust to nearly any weather system that comes your way. It’s worth noting that you don’t have to have any idea what the weather will be in the future to know that your home will stay comfortable.
In other words, the elements of a system communicate through interconnections in pursuit of the goal of the system. The system is always changing, but when strained, it works very, very hard to restore itself to homeostasis. (And natural systems are usually much, much better at doing that than mechanical ones like an HVAC system.)
Once you start thinking about homeostasis, you’ll see it everywhere.
For example, consider someone happily and very recently married. Much of the courtship and early time living together is about establishing homeostasis for this new system.
You gradually learn the signs when your spouse is upset, what the pet peeves are, how to make each other smile, etc. Within a few months, and certainly within a few years, you and your spouse operate within a fairly consistent zone of homeostasis. When something strains that (say a new job, or a move), the system responds in one of three ways: it pushes back to homeostasis, it recalibrates to a new homeostasis, or it collapses.
As a happy example of recalibrating to a new homeostasis, consider that same new family after their first child.
That is an event that is so disruptive to the workings of the system that it must find a new homeostasis, which of course it does. Everything from sleep schedules to social routines to food preferences changes. And then you settle into a new homeostasis, which itself will change slightly over time, but last until the next kid comes along, starting the process over again.
And you see it in your own organizations: how many “change efforts” have you or your company tried and failed? In many cases, the biggest failure is that the forces for homeostasis are too strong. The disruption has to be big enough to shock the system into an existential threat: change or die. You also see this in examples where former enemies cooperate, or bitter rivals come together.
Homeostasis in Action
As a vivid example of both the stabilizing power of homeostasis and the kind of shock — sometimes quite literally — needed to disrupt it, I’ll share a story about San Francisco. (This was first told to me by Jonathan Rosenfeld and I found it so intriguing I went searching for more details.)
Before the 1930s there was regular ferry service throughout San Francisco Bay, including between what’s known as the East Bay and downtown San Francisco. But with the rise of the car and construction of the Bay Bridge, ferry ridership declined precipitously and soon was discontinued between the East Bay and downtown.
As the Bay Area population — and with it traffic and congestion — grew throughout the 20th century, there were repeated calls for reviving the ferry service between the East Bay and downtown. But like many municipal matters, it stagnated within local and regional politics for decades, a chronic victim of homeostasis.
Then on October 17, 1989, the Loma Prieta earthquake struck, dramatically disabling the Bay Bridge and paralyzing traffic.
Within 3 hours, ferry service had resumed between the east bay and downtown San Francisco and it continues to this day.
Maintaining Homeostasis and Health
When working to understand a system, again because of our instinct to construct narratives, we tend to put the most focus on the elements of the system — the actors in the story — and the least on the purpose of the system. Yet that purpose, the goal of the system, tends to have a much more powerful impact on the behavior of the system than either the elements or the interconnections between them.
The inclination to think about a system like a company mechanistically, with parts to be repaired or replaced, may well be a side effect of the way we use metaphors — storytelling again — to make sense of our own minds.
Robert Epstein, a psychologist, author, and magazine editor explains it eloquently in this passage from his essay, “The Empty Brain”:
Artificial intelligence expert George Zarkadakis describes six different metaphors people have employed over the past 2,000 years to try to explain human intelligence.
In the earliest one, eventually preserved in the Bible, humans were formed from clay or dirt, which an intelligent god then infused with its spirit. That spirit ‘explained’ our intelligence — grammatically, at least.
The invention of hydraulic engineering in the 3rd century BCE led to the popularity of a hydraulic model of human intelligence, the idea that the flow of different fluids in the body — the ‘humours’ — accounted for both our physical and mental functioning. The hydraulic metaphor persisted for more than 1,600 years, handicapping medical practice all the while.
By the 1500s, automata powered by springs and gears had been devised, eventually inspiring leading thinkers such as René Descartes to assert that humans are complex machines. In the 1600s, the British philosopher Thomas Hobbes suggested that thinking arose from small mechanical motions in the brain. By the 1700s, discoveries about electricity and chemistry led to new theories of human intelligence — again, largely metaphorical in nature. In the mid-1800s, inspired by recent advances in communications, the German physicist Hermann von Helmholtz compared the brain to a telegraph.
Each metaphor reflected the most advanced thinking of the era that spawned it.
Predictably, just a few years after the dawn of computer technology in the 1940s, the brain was said to operate like a computer, with the role of physical hardware played by the brain itself and our thoughts serving as software.
I would argue that the metaphors Epstein listed have a parallel in how we think about and talk about organizations, and that we’re still using a lot of computer and software metaphors. Think about how many times you’ve heard talk of “upgrading” your organization, or the buzz about concepts like “Lean” or “Agile” as if they were apps to install.
But our teams and companies and industries are no more like machines or computers than our brains are, and when we use incomplete metaphors we limit our ability to accurately understand their behavior.
In her outstanding book from Berret-Kohler, “Leadership and the New Science”, Margaret Wheatley gets right to the core of the limitations of our current structural metaphors when we try to understand systems like a company:
The organization of a living system bears no resemblance to organization charts. Life uses networks; we still rely on boxes. But even as we draw our boxes, people are ignoring them and organizing as life does, through networks of relationships. To become effective at change, we must leave behind the imaginary organization we design and learn to work with the real organization, which will always be a dense network of interdependent relationships.
(And before you object to the term “network” as yet another variation of the computer metaphor, I’ll defend Wheatly by noting that the word originated in the 16th century, and has over time been used to describe everything from thread patterns to canals.)
What might this mean for an team, a company, or even an entire industry?
Well, if we start to think about things more like an actual ecosystem — a collection of those “dense networks of interdependent relationships” — then we can think very differently about how to prepare for the future.
You see, when we look at the living, dynamic systems surrounding us we see remarkable longevity and resilience — despite exactly zero effort expended by those systems at predicting the future.
Nassim Nicholas Taleb, of “Black Swan” fame, describes this in his latest book, “Antifragile”, in talking about how incredibly effective our species as a whole has been at adapting to immense forces of change over time, despite being terrible at predicting the future:
Consider, as a thought experiment, the situation of an immortal organism, one that is built without an expiration date. To survive, it would need to be completely fit for all possible random events that can take place in the environment, all future random events. By some nasty property, a random event is, well, random. It does not advertise its arrival ahead of time, allowing the organism to prepare and make adjustments to sustain shocks. For an immortal organism, pre-adaptation for all such events would be a necessity. When a random event happens, it is already too late to react, so the organism should be prepared to withstand the shock, or say goodbye.
Post-event adaptation, no matter how fast, would always be a bit late. To satisfy the conditions for such immortality, the organisms need to predict the future with perfection — near perfection is not enough. But by letting the organisms go one lifespan at a time, with modifications between successive generations, nature does not need to predict future conditions beyond the extremely vague idea of which direction things should be heading. Actually, even a vague direction is not necessary. Every random event will bring its own antidote in the form of ecological variation. It is as if nature changed itself at every step and modified its strategy every instant.
If life uses networks of relationships, and life thrives amid uncertainty and unpredictability, what are the conditions for a healthy network? And what can we do to help ourselves and our organizations become healthier networks of interdependent relationships?
According to Wheatley, a healthy network needs three things: information, connections, and meaning. You’ll note that neatly echoes Dana Meadows definition of a system, with its elements, interconnections, and purpose.
And recall that our instinct is typically to focus our energy on changing the elements of the system — the people, the tools, the suppliers, the formats. We see cause and effect, and so we try command and control to modify the elements of the system. We reshuffle and reorganize the elements, connect them together on an org chart, and then often as an afterthought, cobble together some form of vision or mission statement.
But when we don’t pay enough attention to the system’s interconnections and purpose, the system will fight our best efforts as it seeks homeostasis.
So rather than command and control, we should instead be thinking the way that nature does, which is in terms of sense and respond (that distinction is at the heart of the “Holocracy” movement, though I much prefer this overview via strategy+business to anything “branded” Holocracy).
That is why even as individual companies or sectors may be fragile or endangered, industries as a whole can remain vibrant and resilient. There is no deliberate attempt to control or change the elements of the larger system. Instead, the system responds naturally by building more connections among its parts, which improves the flow of information and reinforces the system’s purpose and goals.
But What About “Disruptive Innovations?”
It bears pointing out that just because an industry (as a dynamic system) is resilient and adaptable doesn’t mean any particular company or sector will last as long as the bigger system they’re a part of. Systems comprise smaller systems, and are parts of larger ones — one of the most compelling points Taleb makes in “Antifragile” is that often the relative fragility of the individual elements of a system actually makes the larger system much stronger:
So antifragility gets a bit more intricate — and more interesting — in the presence of layers and hierarchies. A natural organism is not a single, final unit; it is composed of subunits and itself may be the subunit of some larger collective. These subunits may be contending with each other. Take another business example. Restaurants are fragile; they compete with each other, but the collective of local restaurants is antifragile for that very reason. Had restaurants been individually robust, hence immortal, the overall business would be either stagnant or weak, and would deliver nothing better than cafeteria food — and I mean Soviet-style cafeteria food. Further, it would be marred with systemic shortages, with, once in a while, a complete crisis and government bailout. All that quality, stability, and reliability are owed to the fragility of the restaurant itself.
The majority of the literature on “disruption” is oriented at helping individual companies compete, and at that level conditions can indeed be harsh.
But let’s look more closely at some of the “classic” examples of disruption, whereby a new entrant begins at the low end of the market with a product that incumbents (and their best customers) find inferior, but which eventually both creates a new, larger market and displaces the incumbents:
- Hydraulic excavators (replacing cable-driven ones)
- Steel mini-mills (replacing vertically integrated mills)
- The progression of floppy disk drives (from 14” to 8” to 5.25” to 3.5” to solid-state)
- The PC (replacing the mini-computer, which in turn replaced the mainframe)
In each case, once-mighty firms were toppled from their perch atop their industries. But each respective industry (construction, manufacturing, and computing) grew larger, stronger, and healthier by the same pattern of disruption that was so damaging to so many individual firms.
It’s no coincidence that every industry has some form of conferences, trade shows, and standards bodies, and that often these emerge during times of strain and stress.
It’s also no coincidence that more often than not, regardless of the industry, you’ll hear people say that the real value of any particular conference or trade show or standards body isn’t the stated theme or purpose. What is the number one reason people attend conferences and trade shows? That’s right, “networking”. It is the system acting to improve its dense network of interdependent relationships.
It is literally what we as human beings are built to do, and by acknowledging it, and by working to create the conditions for a healthy system, a healthy network of interdependent relationships, we strengthen ourselves and the organizations we’re a part of, no matter what the future brings.
The “New Normal” for Publishing
So I think that kind of systemic response is the main reason why industries like publishing can undergo profound change while also remaining quite recognizable over long periods of time. The system adapts and evolves, absorbing new information and if necessary, finding a new homeostasis, a new normal.
And that “new normal” for book publishing doesn’t mean that digital is “done”! On the contrary, digital books and the wider set of technologies surrounding them are now deeply woven into the fabric of what’s “normal” for the system.
Alan Kay famously said, “technology is anything that was invented after you were born,” and just as we don’t think anymore of things like punctuation as “technology” (the hyphen first appeared in continental Europe in the 11th century, and took 200 years to reach England), anyone “born” into publishing today won’t give a second thought to ebooks or social media, they are now just part of the system’s “new normal”.
Digital in publishing isn’t done, it’s just getting boring. Which means it’s just getting started.
This essay was adapted from a talk given at the Firebrand Technologies user conference in Portsmouth, NH in September of 2016.
]]>