

What My Personal AI Agent Setup Actually Looks Like
“In reality it is the maze which remembers, not the mouse.”
— James Gleick, The Information
When I first started using AI, it was always about helping me produce some specific output. A research report, a meeting agenda, even a new workout plan for the gym. I learned over time that the more specific and detailed of a prompt I gave, the better the output.
Later, when I needed another output that used a lot of the same context — perhaps a spreadsheet going to the same audience as the meeting agenda — I’d go back to the previous chat session on the topic, and either continue from there, or have the LLM generate a summary I could use to seed a new chat rather than rehash all of the background from scratch.
But as I tried to scale that up and involve an LLM with more and more areas of responsibility in my work and personal life, managing all of that context quickly spiraled out of control. I’d either try to do too much within a single chat (because that chat session already “knew” a bunch of stuff relevant to a specific project or company or team) or flail in an effort to organize and re-use context and bits of prompts in various scattered files and folders — most of which quickly became stale.
Because for an executive or operator doing knowledge work, any specific output or artifact isn’t usually the hard part. The hard part is maintaining an ever-evolving model of a complex web of interrelated context: What matters right now? What was already decided? Why was that decided? Who is involved? What assumptions are at play? What changed since the last time I looked at this? What issues remain unresolved? Where are the edge cases and pitfalls?
Those mental maps are complex, and any manager or executive will tell you that the hidden costs of “reloading” are very real. Every interruption, every context switch, every multi-day pause forces you to keep reconstructing a mental house of cards that will just come crashing down again with the next shift in attention.
This is the pain point behind endless systems and tools, from Getting Things Done (GTD) to Building a Second Brain: the promise that with the right system and enough discipline, you too can manage all of that context switching.
The first glimpse I got of a potential better way was when I tried out the Claude desktop app, which lets Claude access your local files. Now instead of pasting in or uploading notes and documents, I could just tell Claude where to find the context needed for a specific task. A huge improvement!
But the context keeps changing, which means someone still has to keep all of those notes and prompts and background material organized and up to date, or you end up fighting against stale context — which can be worse than no context at all.
So I reframed the problem away from “how can I use AI to help me produce better output” to “how can I use AI to manage the evolving context across multiple related areas of responsibility in my work and life?”
Because unlike a programmer’s codebase, which usually itself stores the state of the work, a knowledge worker’s “codebase” is spread across docs, spreadsheets, meeting notes, email threads, Slack threads, unstated assumptions, political landmines, and tacit (but usually undocumented) knowledge.
And as I started working with AI and specifically with structured “agents”, the more I realized that for me, that was the real opportunity. Using AI primarily to manage continuity and context over time, rather than primarily to produce artifacts of output.
My setup
“[W]hat people forget is that founders at successful companies have another reason not to have to take so many notes or use so many productivity systems: They have an entire organization that acts as an extension of their intelligence. In a sense, the organization itself is the biggest productivity hack of all — rendering cheap alternatives like note-taking systems or pomodoros obsolete.”
— Dan Shipper, “AI and the Age of the Individual”
LLMs are trained on copious amounts of human interaction and language, so to me it made sense to lean into that and model my workflow around a “team” metaphor. I’m sure you’ve had what I call the “Bob” experience within an organization before: every time a question comes up about a particular topic or system, everyone says “Oh, go ask Bob about that.” Maybe Bob’s the one who built the process or system, or maybe he’s just been around long enough to have seen it all, but everyone knows that when you need to know something about “that thing” — you go ask Bob.
So that’s what I set out to build for myself. A team of agents that would each maintain as much context as possible around a particular domain or area of responsibility. That way, when I needed a new output or had a question related to that domain, I could go to Bob (or Janet, or Patty), and ask them for help, because they’d already “know” enough background to be immediately useful.
But it’s one thing to collect the disparate context needed to help an agent be an effective assistant — it’s quite another to keep that context updated over time.
The good news is that AI agents are very, very good at helping themselves do just that.
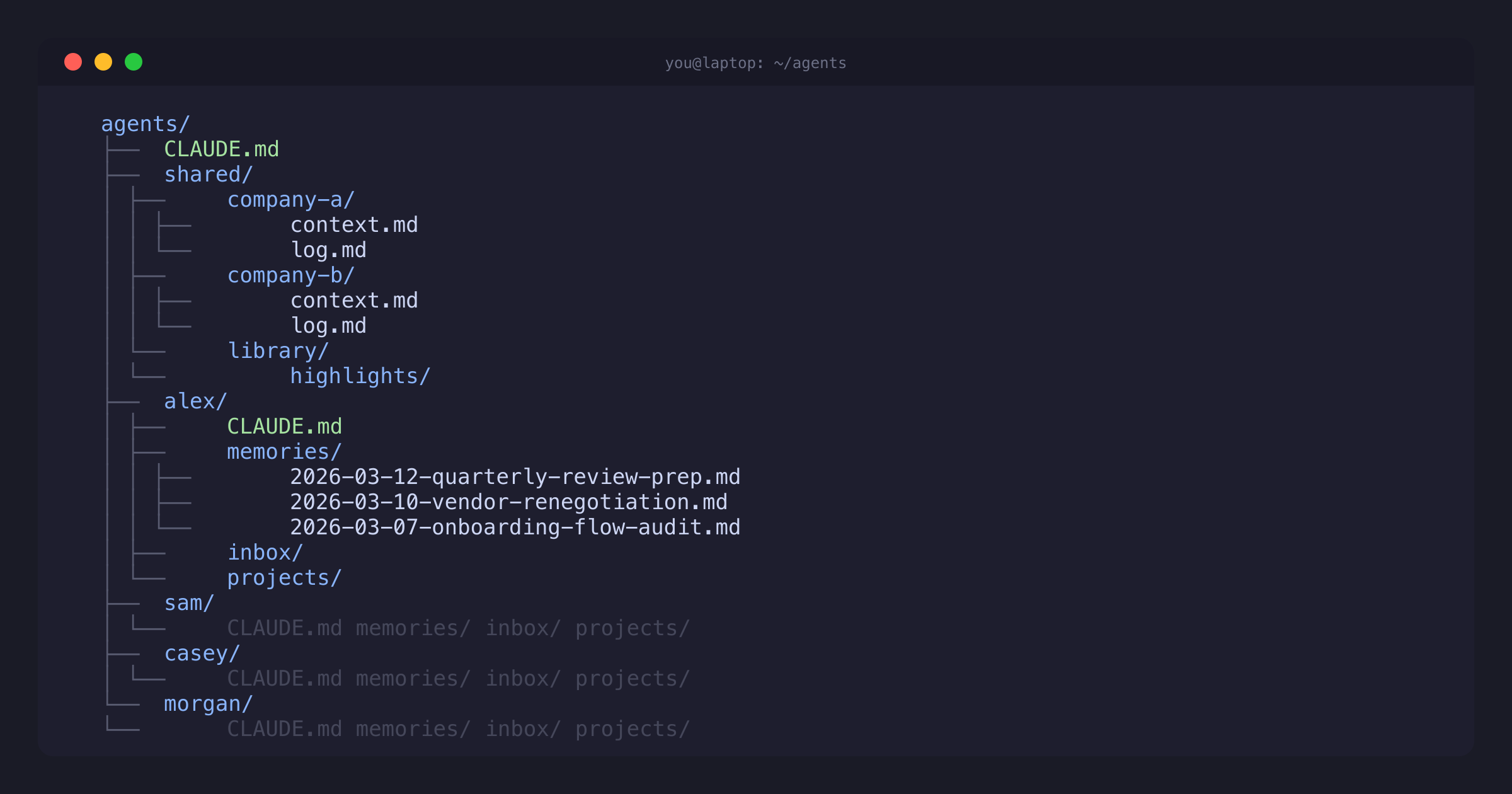
I made a new folder on my computer, and in the folder made sub-folders for multiple agents. Each one has a name and a basic persona, and each one is designed to accumulate and manage knowledge and context for a particular domain. They have detailed instructions about how to keep their own “memories”, and for how to maintain and update information about their particular domain.
At the start of each session, the very first thing they do is load up all of that previous context so we can pick up exactly where we left off the last time. Then the very last thing they do before we wrap up is update all of those memories to reflect what’s new or what’s changed. My interactions with them along the way(researching, writing, analyzing, modeling) gives them realtime information about how the context is evolving, and then they do the work of organizing and processing that information over time.
I’ve also added tools for the agents to easily access email, docs, Slack, and other external sources of context, making it easy for me to direct them to get up to speed quickly on specific items.
Because their context is continually updating, the agents have accumulated a rich understanding of what’s going on, so I don’t have to keep explaining things like projects, priorities, and people. I can just say things like, “Please refresh me on where things stand with the Acme partnership negotiation,” and “OK, which of the product descriptions still need to be updated?”
The main benefit is not that it helps me produce more useful outputs (though it absolutely does1). It’s that it preserves continuity of context over time. It dramatically lowers the cost of returning to hard problems without starting over. It helps maintain the internal map (or really, maps) needed to be effective. And once you’ve experienced that, it’s very hard to go back. For me, the system has stopped feeling like a system or a trick or a hack or a process, and started feeling like essential infrastructure.